5| Security Rules
The syntax, common patterns, and role based access control.
As mentioned before, authentication is knowing who the user is, authorization is knowing what they can do. Now that we have users authenticated, we can write rules that determine what they can do.
What are Security Rules?
Security Rules are the one-stop-shop for protecting data in the database. They act as a bouncer for requests into the database. Do you want to read the users collection? Well, there needs to be a rule that allows that. Otherwise, you’re not getting to the club, I mean database.
Security Rules can feel a little jarring at first because they are their own language and two flavors at that. You might wonder why did Firebase create custom languages instead of using a commonly used language like JavaScript? This is a great first question to ask, because it explains the basics of how Security Rules work.
Security, centralized
A big benefit here is that the logic that determines authorization is located in one spot. In many (but not all) traditional systems, you can have many layers of security logic. You might write security checks on the server, and maybe some within the database itself. With Firebase apps, you write your security in one spot. Yes, you still perform client-side validation.
Why a custom language?
When a request comes into your service (Firestore, RTDB, or Storage) your rules evaluate whether that request is allowed. This means that the operation is held up until the rule is evaluated. If the evaluation takes a long time, that’ll make performance pretty miserable for you and your users. That’s exactly why Security Rules are their own custom language. This language is designed to evaluate quickly and to avoid performance bottlenecks.
Concepts
Security rules start out by declaring what resource they are operating on.
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
allow read, write: if false;
}
}
}In this case we are operating against Cloud Firestore. Then from there it’s all about matching.
Matching
If you’ve ever written an Express JS router or some kind of HTTP routing system, you’ll be right at home with rules. Like a router, you can match paths and then specify your custom logic from there. But since this is a database or storage bucket, you can also think about rules as a way for you to annotate who has access to the data at that path.
app.get('/users/david_123', (req, res) => {
});This matches on the path of the user and even captures their uid within as a variable. Using that uid you usually look up their profile or desired data. Security Rules work just the same way.
match /users/david_123 {
}Match blocks are how you define which path to apply a rule to. When you write match statements for a path for a security rule the path must match at the document level. That means you can’t write a match statement for a “users” collection. It has to match a document in that collection.
This constraint might feel counterintuitive, and you might be wondering “How do I secure all of my users if they are dynamically created?” You can do that with wildcards.
Wildcards
Continuing with the HTTP router example, wildcards are just like wildcards in routing. For an HTTP router, you might want to match on a users/:id path.
app.get('/users/:id', (req, res) => {
const { id } = req.params;
});When a request comes in for that path you’ll generate a page for that specific user given their route parameter. Security Rules work the same way but instead of a colon, you wrap the wildcard in curly braces.
match /users/{uid} {
}You aren’t going to know each and every document in a collection, so given a request for a document you can capture the “id” or whatever route parameter with a wildcard. Our term for a “route parameter” (id) is called a segment variable. This allows you to follow the constraint of matching a specific document while thinking of it as securing an entire collection.
Wildcards can even be recursive. Which is a fancy way of saying you can match for that path you are at, or even for paths below your current path. This is really useful for subcollections that might need to enforce the same rules.
match /users/{id=**} {
allow read: if request.auth.uid != null;
}Consider a data structure where you have a “users” collection, and you create subcollections keyed to a user’s id. You could have users/{id}/todos and all sorts of other collection based information specified to that single user.
Wildcards and especially the recursive kind are powerful because they can secure a variable number of paths, but what happens when you have two match statements that match on the same path?
Overlapping paths
Sometimes you’ll find yourself writing broad match statements. The general rule is that if any rule allows access from either match statement, the rule is allowed. If you grant access to read in the one path you can’t revoke that access somewhere else.
Allow statements
Inside of a match block is the allow statement. This is the heart of security rules. The allow statement takes a method and then an expression.
match /users/{uid} {
allow read: if false;
}The allow statement is made of two parts: the permissions and the expression.
Permissions
In Firestore there are two categories: read and write. These permissions determine that kind of operation should be allowed.
read
The read permission checks for any type of read to the database. The read permission is an alias for lower level permissions as well:
get- A single documentlist- Requesting documents within a collection
Keep this granularity in mind if you require specific logic for a different type of read.
write
The write permissions checks for any type of write operation. This permission is an alias for update like operations.
createupdatedelete
It’s really common to find yourself using these permissions. Create logic is often different than updating an existing document. This is where you can ensure all of that is being enforced.
Using multiple permissions
You can use multiple allow statements in one match black as well. You can define access for reads differently than writes. Creates differently than updates, which is really helpful when validating the schema of an object.
match /users/{uid} {
allow read: true;
allow create: if request.auth.uid == uid;
}Yes, you SQL fans you can specify the structure and types of documents with Security Rules.
Expressions / Variables
The permission is followed by an expression. If the expression evaluates to true, then the rule is allowed. Because Security Rules come with an entire set of variables that allow you to look at the incoming request, the identity of the user requesting, the data of the request (if it’s write operation), the resource/data at the path being requested, and a lot of other useful information to allow you to sophisticated access systems
match /users/{uid} {
allow read: true; // public for everyone
allow write: if request.auth.uid == uid; // only a user can edit their data
}Security rules have a set of variables that are essential for making secure rules.
requestresourcetimemath
And! There’s even more. However, most of the time you’re going to be using request and resource variables. So let’s break those down.
Getting the user
If a user is logged in, you can get their uid within the request.auth object. This is verified by the Firebase backend so we know it’s the legitimate user.
match /users/{uid} {
allow read, write: if uid == request.auth.uid;
}This is one of the most simple but essential rules to know in Firebase. We’re capturing the uid with a wildcard in the path, and then securing the documents within that collection by asserting that the wildcard must match the uid of the currently authenticated user.
This is another reason why it’s important to think about what you are keying off of when you structure your data in Firestore. If you use the uid key it can make your rules really easy. However, you can still get the same security with a generated ID.
match /users/{uid} {
allow read: if request.auth.uid = uid;
}Getting the active document’s data
Using the resource variable you can get the resource being requested. The resource variable itself has a property of data where you can access the current data stored at the document.
match /users/{uid} {
allow read: if resource.data.uid == request.auth.uid;
}This data value can be null if no document exits. The resource variable contains the existing document data. But what about the data that is being sent up from the client that is attempted to be written to the database?
Getting the attempted data update
The request object contains another propery named resource. This is different than the top level resource variable. This contains the data that is being attempted to be saved to the database.
match /users/{uid} {
allow read: if request.resource.data.name == 'david';
}This rule is fairly useless, but it demonstrates that you can acess the data before the write has write has been comitted. Using this data you can ensure that the new data conforms to a schema.
It’s important to note that in the case of an update operation, you will likely send only a partial object. Within the request.resource.data object, Firetore will “hydrate” the object so it contains all the properties it would have if it was accepted.
Validating schema
NoSQL itself is schemaless at the database level. However, with Security Rules you have a layer to enforce structure and types before writes can succeed.
There are a few main aspects of schema validatation, enforcing types, fields, and changes.
is
The is keyword will check if a value is a specific type.
match /users/{uid} {
allow write: if request.resource.data.name is string &&
request.resource.data.age is number &&
request.resource.createdAt is timestamp &&
request.resource.score is float;
}With Firestore you have an entire set of types at your disposal to check from.
You might have an old legacy UI/system that is still sending values as incorrect types. In some cases you’ll be able to coerce them.
match /users/{uid} {
allow write: if int(request.resource.data.score) is int;
}This rule will coerce the type to an int and if it fails it will reject the read. Now, This rule ensure that all expected values will be their given types, but what about unexpected values? This rule does limit what can be added to the document.
keys
To ensure that an object has the structure you require, you can use the keys() function.
match /users/{uid} {
allow write: if request.resource.data.name is string &&
request.resource.data.age is number &&
request.resource.createdAt is timestamp &&
request.resource.score is float &&
request.resource.data.keys().hasOnly([
'name',
'age',
'createdAt',
'score',
]);
}The keys() function exists on any type that is a Map, and resource.data is a Map. This keys() function returns List which as entire set of functions for asserting values on the Map. In this case we’re using the hasOnly() function that asserts that there will only be a specific set of keys on the update. If you wan tot be more permissive, you can use the hasAll() function to make sure it at least has the values provided. You can even more permissive with the hasAny() function, which looks for the existence of at least one value provided.
It’s important to note that without restricting on the keys, this rule will still reject if the values being checked for their type do not exists. Specifying hasAll() or hasAny() in addition in those cases would be redundant.
Now it’s time for something a little more complex. After an object is created, what if we wanted certain fields to be immutable? How would check for that?
MapDiff
Firestore has a special type called a MapDiff, that is the result of comparing two Map objects. This diff object gives you a set of functions to analyze the comparison.
match /users/{uid} {
allow update: if request.resource.data
.diff(resource.data)
.unchangedKeys()
.hasOnly(["createdAt"])
}This rule ensures that the createdAt field cannot be changed after being updated. The unchangedKeys() function returns what keys were not modified in the difference between the new data update and the existing data.
The MapDiff object also contains multiple other functions see what keys were added, changed, removed.
Between request.resource and resource you can access data from an update or at that path in the database. However, what if you need to check data from another spot in the database?
Reading data within rules
Security rules allow you to specify a path and retrieve the data from that document and you can compose these paths with variables and wildcards.
get()
The get() function allows you to specify a full path to an document in the database to retrieve its data.
match /secretDocs/{id} {
allow read: if get(/databases/$(database)/documents/admins/$(request.auth.uid)).data.role == 'admin'
}This rule looks if a user in the /admins/{uid} document and has a role of “admin”. One thing you’ll notice is that you have to specify the fully qualified path to the document. The second you’ll notice is that variables are interpolated in that via a $(variable) syntax. This type is referred to as a Path and there’s even some tricks you can do with them as well, but that’s for another day.
It’s only been a bit of a tour through Security Rules, but we’ve looked a lot of advanced situations. The code we’ve written however is rather verbose, which makes sense because it we haven’t abstracted it into any readable or reusable structures… like functions.
Cleaner code with functions
It is my opinion that you should avoid writing expressions inside of a match block (outside of simple situations that is). Security Rules allows you to abstract logic into functions for readablity and reuse.
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
function isUserOwned(pathUid) {
return request.auth.uid == pathUid;
}
match /users/{uid} {
allow read: isUserOwned(uid);
}
}
}This rule uses a function to abstract an expression that evaluates if the currently logged in user owns the data at that document path. By abstracting it out into its own function its far more readable and it can be used in other rules.
One thing you may have noticed, the isUserOwned() function takes in a pathUid parameter but uses the global request object.
Scoping
Functions in Security Rules follow a specific scope. They have access to all global variables, but they also have access to wildcard variables as well. The previous function could have been written like this:
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
function isUserOwned() {
return request.auth.uid == uid;
}
match /users/{uid} {
allow read: isUserOwned();
}
}
}This relies in the {uid} wildcard being present, which will work in many cases. However, I find that its a best practice to try to keep your functions are predictable and readable as possible. Relying on variables that may not be within scope in other rules could lead to trouble, so keep everything as explicit as possible.
Speaking of trouble. How do you know that your rules actually work? How can you be sure that when you make changes you won’t be introducing bugs or a regression?
Workflow
You write rules one of two ways: write them directly in the Firebase Console, or write them locally within your project and deploy with the Firebase CLI.
Start with the CLI
The console is a good option for sample apps or hobby projects. However, it’s a best practice to develop rules locally and deploy with the CLI. This allows your rules to be within source control for your project and makes it easier for teams to collaborate.
firebase init firestore emulatorsWrite unit tests
In addition you can actually write unit tests against your security rules to make sure they don’t break critical use cases between pushes to production.
Firebase provides a unit testing library for this purpose.
npm i -D @firebase/rules-unit-testingThis allows you to write your tests locally and then run unit tests against them using the Emulator Suite. It’s all starts by creating a test environment.
import testing from "@firebase/rules-unit-testing"
import { readFileSync } from 'fs';
const testEnv = await testing.initializeTestEnvironment({
projectId: 'frontend-masters-firebase',
firestore: {
rules: readFileSync('firestore.rules', 'utf8'),
host: 'localhost',
port: 8080,
},
});This environment has a lot of useful methods such as creating authenticated and unauthenticated contexts to run writes and reads to the Emulator.
test('An authenticated user can write their profile', async (t) => {
const context = testEnv.authenticatedContext('david_123');
const userDoc = context.firestore().doc('users/david_123');
const result = await testing.assertSucceeds(userDoc.set({ name: 'Im david' }));
t.is(result, undefined);
});This example creates an authenticated context with a fake uid and then tries to write to a document that is expected to succeed. The assertSucceeds function will throw if the write fails. You can also test for failures wiht the assertFails function.
Monitor requests in the Emulator UI
When you’re writing your rules you’ll run into problems and unexpected situations. Sometimes you’ll expect a rule to fail, but it will pass. How can get more information? The Emulator UI has a tool called the Request Monitor.
While the emulator is running the Request Monitor will show you every request, the line of code that either allowed or rejected the request, and information about the rules environment.
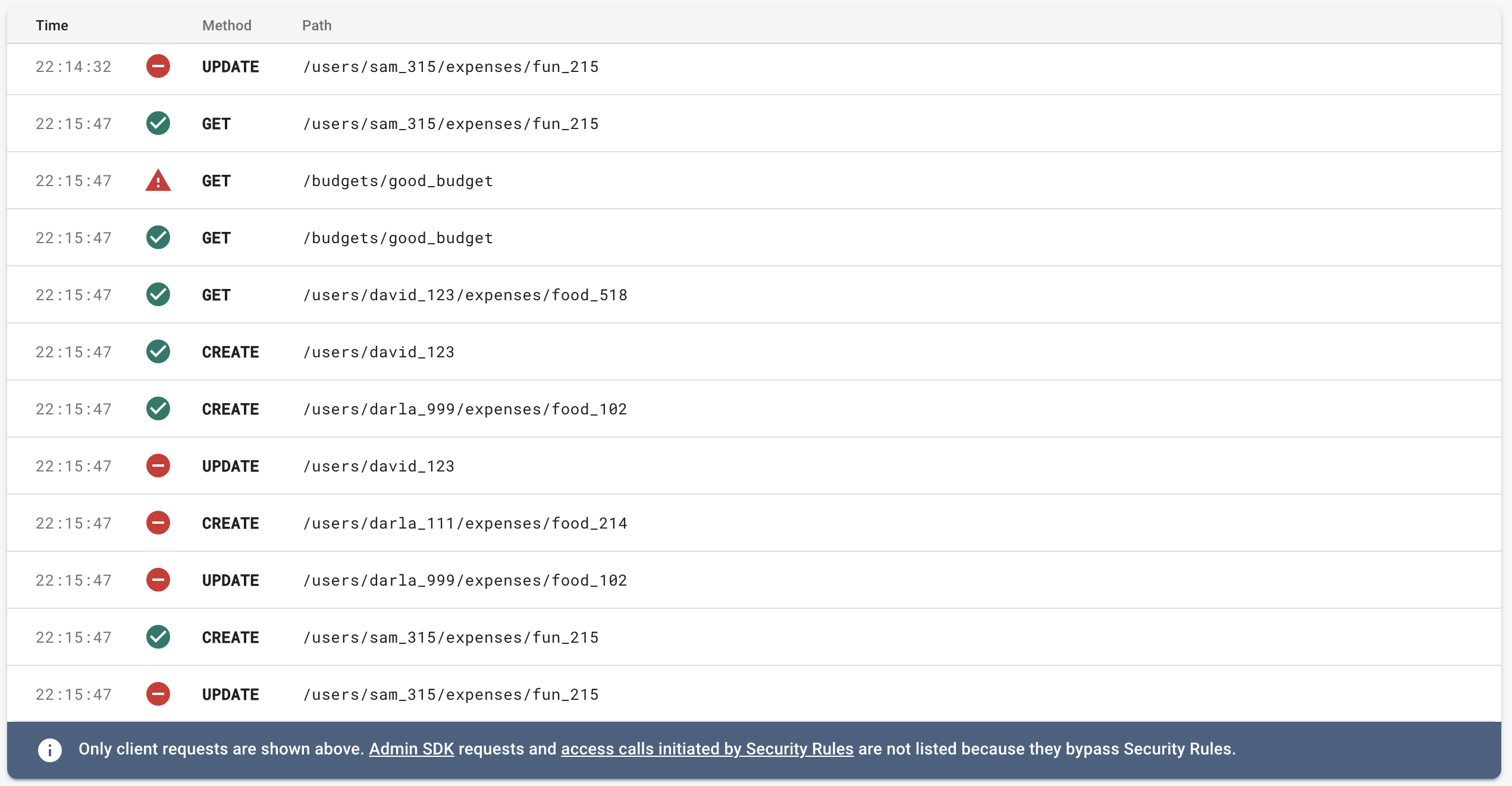
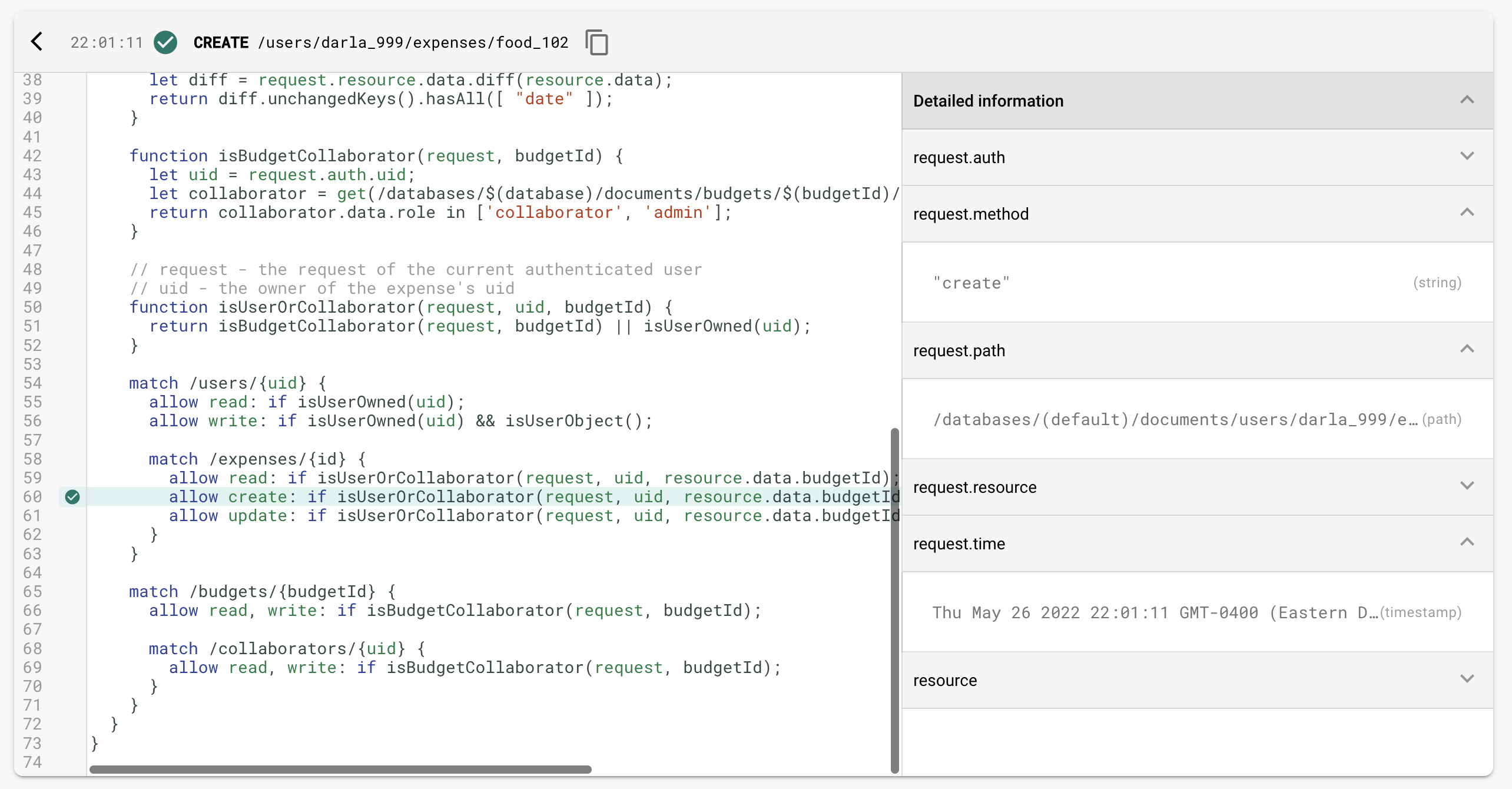
This is extremely helpful when debugging and we’re going to be using it extensively in the next exercise.
Exercise
Now we’re going to take the time to apply everything we just learned.
- cd /5-security-rules/start
- npm i
- npm run emulators
- # Open another terminal tab
- npm test